01.10.2012 01:53
Net-installing Arch Linux
Recently I had to figure out the most efficient way of net-installing
Arch Linux on remote servers
that fits into the deployment process, with many other operating
systems, which runs a DHCP and TFTP daemons serving
various operating system images.
The Arch
Linux PXE
wiki put me on the right track and I downloaded the
archboot-x86_64
ISO, which I temporarily mounted, so I can copy the key parts of
the image:
# wget http://mirrors.kernel.org/archlinux/iso/archboot/2012.06/archlinux-2012.06-1-archboot-x86_64.iso # mkdir /mnt/archiso # mount -o loop,ro archlinux-2012.06-1-archboot-x86_64.iso /mnt/archisoLet's say the TFTP daemon serves images using pxelinux, chrooted in /srv/tftpboot. The images are stored in the images/ sub-directory and the top level pxelinux.cfg configuration gets copied from the appropriate images/operating-system/ directory automatically based on the operating system selection in the provisioning tool:
# mkdir -p images/arch/arch-installer/amd64/ # cp -ar /mnt/archiso/boot/* images/arch/arch-installer/amd64/The boot directory of the archboot ISO contains the kernel and initrd images, and a syslinux installation. I proceeded to create the pxelinux configuration to boot them, ignoring syslinux:
# cd images/arch/
# mkdir arch-installer/amd64/pxelinux.cfg/
# emacs arch-installer/amd64/pxelinux.cfg/default
prompt 1
timeout 1
label linux
kernel images/arch/arch-installer/amd64/vmlinuz_x86_64
append initrd=images/arch/arch-installer/amd64/initramfs_x86_64.img gpt panic=60 vga=normal loglevel=3
# ln -s arch-installer/amd64/pxelinux.cfg ./pxelinux.cfg
To better visualize the end result, here's the final directory layout:
arch-installer/I left the possibility of including i686 images in the future, but that is not likely ever to happen due to almost non-existent demand for this operating system on our servers. Because of that fact I didn't spend any time on further automation, like automated RAID assembly or package pre-selection. On the servers I deployed assembling big RAID arrays manually was tedious, but really nothing novel compared to dozens you have to rebuild or create every day.
arch-installer/amd64/
arch-installer/amd64/grub/*
arch-installer/amd64/pxelinux.cfg/
arch-installer/amd64/pxelinux.cfg/default
arch-installer/amd64/syslinux/*
arch-installer/amd64/initramfs_x86_64.img
arch-installer/amd64/vmlinuz_x86_64
arch-installer/amd64/vmlinuz_x86_64_lts
pxelinux.cfg/
pxelinux.cfg/default
From a fast mirror the base operating system installs from the Arch [core] repository in a few minutes, and included is support for a variety of boot loaders, with my favorite being syslinux which in Arch Linux has an excellent installer script "syslinux-install_update" with RAID auto detection. I also like the fact 2012.06-1 archboot ISO still includes the curses menu based installer, which was great for package selection, and the step where the base configuration files are listed for editing. Supposedly the latest desktop images now only have helper scripts for performing installations - but I wouldn't know for sure as I haven't booted an ISO in a long time, Arch is an operating system you install only once, the day you buy the workstation.
Another good thing purely from the deployment standpoint is the rolling releases nature, as the image can be used to install the latest version of the operating system at any time. Or at least until the systemd migration which might obsolete the image, but I dread that day for other reasons - I just don't see its place on servers, or our managed service with dozens of proprietary software distributions. But right now, we can deploy Arch Linux half way around the globe in 10 minutes, life is great.
26.08.2012 03:35
More on Redis
In managed hosting you're not often present in design stages of new
applications and sometimes you end up supporting strange
infrastructure. Or at least that was my experience in the past. So
little by little I found my self supporting huge
(persistent) Redis databases, against
my better judgment.
Someone sent me a link to
the Redis Sentinel
beta announcement
last month. It may even make it into the 2.6 release... but
all of this I had to implement on my own long ago. A lot of developers
I supported didn't even want to use the 2.4 branch (in my
opinion just the memory fragmentation improvements are more than
enough reason to ditch 2.2 forever). Another highly
anticipated Redis feature,
the Redis Cluster,
may not even make it into the 2.6 release. That's too bad,
there's too much features with Redis that are always "just around the
corner", yet I have a feeling I'll be supporting Redis 2.4 for at
least another 3 years, with all its flaws and shortcomings (I
scratched the surface in my last article with AOF
corruption, and not-so-cheap hardware needed for reliable persistent
storage).
Typically I would split members of a Redis cluster across 2 or more
power sources and switches. But that's just common sense for any HA
setup, as is not keeping all your masters together. Redis doesn't have
multi-master replication so a backup 'master' is always passive, and
is just another slave of the primary with slaves of its own. If the
primary master fails only half of the slaves have to be failed-over to
the backup master. This has its problems (ie. double complexity of
replication monitoring by the fail-over agents), but the benefits
outweight failing-over a whole cluster to the new master. That could
take half a day, as fail-over is an expensive operation (it is a full
re-sync from the master). You can find replication implementation
details here.
If you can't allow slaves to serve stale data (tunable
in redis.conf) you need enough redundancy in the pool to be
able to run at half capacity for at least a few hours, until at least
one of the outdated slaves is fully re-synced to its new master. And
that finally brings me to knowing when is the right time to
fail-over.
Any half decent load balancer can export the status of a backend pool
through an API, or just a HTTP page (if yours can't it's time to use
the open source HAproxy). That
information is ripe for exploiting to our advantage, but we need to be
weary of false positives. I can't share my own solutions, but you will
want all N slaves confirming that the master pool is truly degraded,
and initiate fail-overs one by one to avoid harmonics if you are
serving stale data, or all at once if you aren't. For all that you
will need them to communicate with each other, and
a simple message broker can do
the job well.
As I am writing these last notes I realized I haven't mentioned
another fundamental part of any Redis deployment I do - backups. This
article documents
the persistence
implementation in Redis, and explains that
the RDB engine snapshots are good for taking
backups. RDB is never modified directly, and snapshots are renamed
into their final destination atomically only when they are
complete. From here it's trivial to write a script that initiates a
background save, waits until it's done and transfers the fresh
snapshot off site.
05.03.2012 00:06
Infrastructure you can blog about
I spent last 5 months planning and building new infrastructure for one
of the biggest websites out there. I was working around the clock
while developers were rewriting the site, throwing away an ancient
code base and replacing it with a modern framework. I found no new
interesting topics to write about in that time being completely
focused on the project, while the RSS feed of this journal was
constantly the most requested resource on the web server. I'm sorry
there was nothing new for you there. But I learned some valuable
lessons during the project, and they might be interesting enough to
write about. Everything I learned about Puppet, which was also a part
of this project, I shared in
my previous
entry. I'll focus on other parts of the cluster this
time.
Here's a somewhat simplified representation of the cluster:
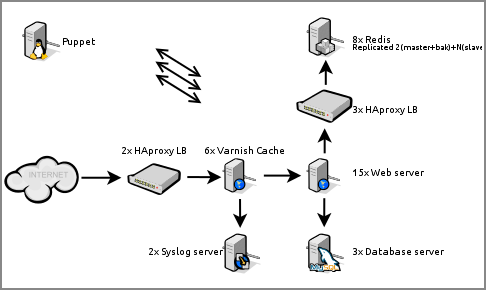
Following the traffic path first thing you may ask your self is
"why is Varnish Cache behind HAproxy?". Indeed placing it in
front in order to serve as many clients as soon as possible is
logical. Varnish Cache is
good software, but often unstable (developers are very quick to fix
bugs given a proper bug report, I must say). Varnish Cache plugins (so
called vmods) are even more unstable, crashing varnish often
and degrading cache efficiency. This is why HAproxy is imperative in
front, to route around crashed instances. But it's the same old
HAproxy that has proven it self balancing numerous high availability
setups. Also, Varnish Cache as a load balancer is a nice try, but I
won't be using it as such any time soon. Another thing you may ask is
"how is Varnish Cache logging requests to Syslog when it has no
Syslog support?". I found FIFOs work good enough - and remember
traffic is enormous, so that says a lot.
Though with a more mature threaded implementation I can't see my self
using Rsyslog
over syslog-ng
on big log servers in the near future. Hopefully threaded syslog-ng
only gets better, resolving this dilemma for me for all
times. Configuration of rsyslog feels awkward (though admittedly
syslog-ng is not a joy to configure either). Version packaged in
Debian stable has bugs, one of which made it
impossible to apply different templates to different network
sources. Which is a huge problem when it's going to be around for
years. I had to resort to packaging my own, but ultimately dropped it
completely for non threaded syslog-ng which is
working pretty good.
Last thing worth sharing are Redis
experiences. It's really good software (ie. as alternative
to Memcached) but ultimately I
feel disappointed with the replication implementation. Replication,
with persistence engines in use, and with databases over 25GB in size
is a nightmare to administrate. When a slave (re)connects to a master
it initiates a SYNC which triggers a SAVE on the
master, and a full resync is performed. This is an extremely expensive
operation, and makes cluster wide automatic fail-over to a backup
master very hard to implement right. I've also
experienced AOF
corruption which could not be detected
by redis-check-aof. This makes BGREWRITEAOF jobs
critical to execute regularly, but with big databases this is another
extremely expensive operation, especially if performed under
traffic. The following has proven it self as a best solution for high
performing Redis servers; 4+x147GB 15k SAS disks in (h/w) RAID10, and
Xeon 5000 series CPUs.
While working on this the running joke was I'm building infrastructure
you can blog about (but otherwise do little else with it). But it does
do a little more than just look impressive on paper.
06.11.2011 00:17
Pulling strings
After one year of managing a network
of 10
servers with Cfengine I'm currently building two clusters of 50
servers with Puppet (which I'm using for the first time), and have
various notes to share. With my experience I had a feeling Cfengine
just isn't right for this project, and didn't consider it
seriously. These servers are all running Debian GNU/Linux and
Puppet felt natural because of the
good Debian
integration, and the number of users whom also produced a lot of
resources. Chef was out of the picture soon because of
the scary
architecture; CouchDB, Solr
and RabbitMQ... coming from Cfengine this seemed like a bad
joke. You probably need to hire a Ruby developer when it
breaks. Puppet is somewhat better in this regard.
Puppet master needs Ruby, and has a built-in file server using
WEBrick. My first disappointment with Puppet was
WEBrick. Though
PuppetLabs claim you can scale it up to 20 servers, that
proved way off, the built-in server has problems serving as little as
5 agents/servers, and you get to see many dropped connections and
failed catalog transfers. I was forced to switch to Mongrel
and Nginx as frontend very early in the project, on both
clusters. This method works much better (even
though Apache+Passenger is the recommended method now from
PuppetLabs), and it's not a huge complication compared to WEBrick (and
Cfengine which doesn't make you jump through any hoops). Part of the
reason for this failure is my pull interval, which is 5 minutes with a
random sleep time of up to 3 minutes to avoid harmonics (which is
still a high occurrence with these intervals and WEBrick fails
miserably). In production a customer can not wait on 30/45 minute pull
intervals to get his IP address whitelisted for a service, or some
other mundane task, it must happen within 10 minutes... but I'll come
to these kind of unrealistic ideas a little later.
Unlike the Cfengine article I have no bootstrapping notes, and no
code/modules to share. By default the fresh started puppet agent will
look for a host called "puppet" and pull in what ever you defined to
bootstrap servers in your manifests. As for modules, I wrote
a ton of code and though I'd like to share it, my employer owns
it. But unlike Cfengine v3 there's a lot
of resources out there for
Puppet which can teach you everything you need to know, so I don't
feel obligated to even ask.
Interesting enough, published modules would not help you get your job
done. You will have to write your own, and your team members will have
to learn how to use your modules, which also means writing a lot of
documentation. Maybe my biggest disappointment is getting
disillusioned by a lot of Puppet advocates and DevOps prophets. I
found articles and modules most of them write, and experiences they
share are simplistic - have nothing to do with the real world. It's
like they host servers in (magic?) environments where everything is
done in one way and all servers are identical. Hosting big websites
and their apps is a much, much different affair.
Every customer does things differently, and I had to write custom
modules for each of them. Just between these two clusters a module
managing Apache is different, and you can abstract your code a lot but
you reach a point where you simply can't push it any more. Or if you
can, you create a mess that is unusable by your team members, and I'm
trying to make their jobs better not make them miserable. One customer
uses an Isilon NAS, the other has a content distribution
network, one uses Nginx as a frontend, other has chrooted web servers,
one writes logs to a NFS, other to a Syslog cluster... Now imagine
this on a scale with 2,000 customers and 3 times the servers and most
of the published infrastructure design guidelines become
laughable. Instead you find your self implementing custom solutions,
and inventing
your own rules, best that you can...
I'm ultimately here to tell you that the projects are in a better
state then they would be with the usual cluster management policy. My
best moment was an e-mail from a team member saying "I read the
code, I now understand it [Puppet]. This is fucking
awesome!". I knew at that moment I managed to build something
good (or good enough), despite the shortcomings I found, and with
nothing more than
using PuppetLabs
resources. Actually, that is not completely honest. Because I did buy
and read the
book Pro
Puppet which contains an excellent chapter on using Git
for collaboration on modules between sysadmins and developers, with
proper implementation of development, testing and production
(Puppet)environments.
29.09.2011 03:45
Reamde
I received a copy
of REAMDE
by Neal Stepehenson, his latest book, two weeks before publication
date and slowly worked my way through it. Having finished it I can say
I really liked it. A lot of reviewers are disappointed that it wasn't
nearly as complex as his earlier work, like Cryptonomicon
and Anathem. But it was still a 1200 pages volume of
Stephenson awesomeness. This is a thriller set in modern day, not an
SF book.
Reason I enjoyed it a lot are the characters, a lot of them were
(black or whitehat) hackers, sysadmins, programmers and
gamers. Perhaps I felt closer to them than some readers did, who might
have expected an epic historical novel or SF from
Stephenson.
Book opens up with Richard, a CEO of Corporation 9592 that
produces a massive online role-playing game called T'Rain. Somewhat
like WoW but with a twist, the idea behind the world and how it was
built is one of the best chapters in the book. Some hackers found a
way to exploit a vulnerability shared by T'Rain players and wrote
malware that encrypts their data with PGP and holds them for
ransom. Payment is done in gold in the T'Rain world. At some point
they ransom data of some carders, and their handlers who are
very bad people and all hell breaks loose. Mobsters and terrorist
cells get involved and story jumps to multiple continents. Neal
Stephenson once said he likes making a good yarn, and he delivered on
it again.
26.06.2011 01:10
Building a VDR with Arch Linux
Early in the last decade I had a so called SatDSL
subscription, it was very expensive but the only way to get decent
bandwidth. With the subscription I received a DVB-S PC tuner,
a Technisat
SkyStar2. A few years later when the subscription ran out I was
left with the tuner and got interested in other ways of using the
hardware. Those were some dark times for content providers, encryption
systems
were getting
hacked left and right. The Wired magazine
ran a
great piece a few years ago about this period. Personally I was
more interested in network
traffic at the time, as a lot of it was not
encrypted.
I used VDR software back then to
build an approximation of a commercial SAT receiver. A friend put
together an infra-red receiver for use
with LIRC and I was set. With the
rising popularity of HDTV and
the DVB-S2 standard
my current 'receiver' was getting outdated. It had a Duron
1200 CPU, with 300MB of SDRAM and a 320GB of storage. I
was putting money on the side for several years to build a replacement
(and get an appropriate HD TV set), and finally did it this
year. These past few months I
used Arch Linux with VDR, and
built it piece by piece as a hobby. On the hardware side I used:
MBO: Asrock M3AUCCI didn't go with one of the Ion systems, because I don't watch that much TV, and the box will be put to many other uses (backups, TOR gateway, media streaming, distributed compiling, etc.). Every piece was carefully selected, and folks on the VDR mailing list helped me choose a suitable graphics card for HDTV, with good VDPAU support. As usual with Linux even that careful selection wasn't enough to ensure a smooth ride.
CPU: AthlonII X3 455
RAM: 4GB DDR3
HDD: 1TB disks (RAID1)
GFX: GeForce GT240 (VDPAU)
DVB: SkyStar HD2 (DVB-S2 tuners)
LCD: Philips 43" HDTV
The sound-card drivers were deadlocking the machine, and it took a few days of experimentation to resolve it. The SkyStar HD2 cards work great with the mantis driver, but support for their infra-red receiver is missing. However experimental support is available through a patch published on the Linux-media mailing list, earlier this year.
All my previous VDRs were powered by Slackware Linux, and I developed some habits and preferences in running VDR. So I didn't use the ArchVDR project, or VDR packages, although they are good projects. I prefer to keep every VDR installation under a single directory tree, with the one currently in use always being symlinked to /opt/VDR. I swap them a lot, always patching (liemikuutio, ttxtsubs...), and testing a lot of plugins.
Instead of using runvdr and other popular scripts for controlling VDR I wrote my own script long ago. I call it vdrctl, it's much simpler but provides extensive control over loaded plugins and their own options, and has support for passing commands directly to a running VDR with svdrpsend. As the window manager I used awesome this time, opposed to FVWM that can be seen in this old gallery. Awesome runs in a fullscreen layout, and with some useful widgets.
For playing other media my long time favorite is Oxine, a Xine frontend well suited for TV sets. But I don't use its VDR support as one might expect (I use the vdr-xine plugin with regular xine-ui), instead I connect VDR with Oxine through the externalplayer-plugin. It's special in that it breaks the VDR connection to LIRC prior to launching an external player allowing to seamlessly control both applications.
Arch Linux makes it easy to build your own packages of all the media software to include VDPAU support. Official mplayer already has it, Xine is available in the AUR as xine-lib-vdpau and so on. But even more important, the good packaging infrastructure and management makes it easy to build and maintain custom kernels (for IR support ie.). It truly is the perfect VDR platform.
22.06.2011 03:57
org-mode and the cycle
 I go
through 50 or so support tickets, and Nagios alerts that must
be acted on, in a given shift. There's also long term projects to
manage. That's a lot of work, and a lot of
distractions for a single work day. To keep it all under
control I turned to the book
"Time
Management for Sysadmins" after enjoying some other books of the
author. The book promotes a "cycle" system, with one TODO list/sheet
per day, where all unfinished items from the previous day are
transferred onto the next, and a few minutes invested in prioritizing
and planning the day. There's much more to the method, but that's the
gist of it, avoiding the "never ending TODO list of
DOOM".
I go
through 50 or so support tickets, and Nagios alerts that must
be acted on, in a given shift. There's also long term projects to
manage. That's a lot of work, and a lot of
distractions for a single work day. To keep it all under
control I turned to the book
"Time
Management for Sysadmins" after enjoying some other books of the
author. The book promotes a "cycle" system, with one TODO list/sheet
per day, where all unfinished items from the previous day are
transferred onto the next, and a few minutes invested in prioritizing
and planning the day. There's much more to the method, but that's the
gist of it, avoiding the "never ending TODO list of
DOOM".
Tools of choice for the author are pen and paper, or a PDA is
suggested as an alternative. I wouldn't carry a journal and don't own a
PDA, but I already depended
on org-mode heavily for my personal
projects management and nothing could replace that, really. So while I
was planning how to apply this new found wisdom and pair it with
org-mode I came up with a system I wish to describe here. I
wanted to do that for a long time, even though it's very specific to
my needs, so most likely nobody can make use of it as is. But perhaps
it gives you ideas, and even that would be great
Org-mode is a top notch project management tool, inside a good
editor. Great tools for the job. Yet it's very easy to fall into the
"list of doom" trap. In the context of org-mode its gurus actually
recommend keeping big lists with a small number of files, because of
good agenda overview and unlimited possibilities of org-mode... but I
decided to avoid it and imitate the system the book promotes with one
list per day, and project in my case (author splits them into
sub-tasks, for day lists). If you're familliar with the cycle system
and thinking it doesn't make sense read on, org-mode agenda view is
the key.
I start my day with a terminal emulator, and I realized it would be
best to have a dedicated tool that can be used from the command
line. So I
wrote mkscratch,
a simple tool that sets me up with a scratchpad for the day, helps
managing the old pads, but also pads of long term projects. It's not
actually that specific to org-mode, yet it was written with it in mind
so headers and file extensions reflect that. But it is easily a
general purpose editor wrapper for creating scratchpads or project
pads.
This is how I tie it all together, day-to-day pads are
in ~/work/pads, and once invoked mkscratch creates a
pad for the day, if one doesn't already exist, and
links ~/pad.org to
~/work/pads/MM-DD.org. Then it starts Emacs if not already
running, and opens the pad for the day. I might have scheduled a task
days or months in advance and created a pad for that day, then only
linking of ~/pad.org is performed and editor is opened. Long
term projects get their own directories below
~/work/projects (because projects have other files as
baggage), with some project identifier as the directory name, while
the main pad for every project is
called project.org. This is of some importance (see
the .emacs snippet below).
A good part of the author's cycle system is maintaining a calendar
with meetings and project deadlines meticulously marked. From the
calendar items are copied onto the list for the day when their time is
up (during those few minutes of planning, before the day starts or at
the end of the previous day). While contemplating how to translate
that to org-mode I realized using the Agenda View as is will
do just fine, if only I could gather all scheduled items and
approaching deadlines from all the files (pads and projects) into this
single view. Even though it's not a very conventional usage pattern
for org-mode (remember, we have up to 300 files near the years end),
it can be done easily in .emacs:
;; Files that are included in org-mode agenda
(setq org-agenda-files
(cons "~/work/pads/"
(file-expand-wildcards
"~/work/projects/*/project.org"))
)
One of
my past
articles described connecting my window manager with org-mode for
taking quick notes. I use the same method now for appending to pad
files, not always, but it's very useful to quickly store a task when
you're in the middle of something. A few years ago I wrote another short article on org-mode, using it for project management while freelancing, it describes a different method but a part of it focused on using GPG to encrypt project files. The same can be applied here. EasyPG is now a part of Emacs, and every pad can be encrypted on the fly, and decrypted without any overhead in usage (even more so when using the GPG agent).
05.04.2011 03:12
LILO to syslinux migration
I've been using LILO for a long time, from my first GNU/Linux
installation. Some people have the idea that it's a dead project, but
it's not, development
is still
active. It never failed to boot for me. Until last night, when it
failed to use an XZ compressed
Linux v2.6.38.2. I would never give up LILO
for Grub, but I was contemplating a switch
to syslinux
after watching
the Fosdem
talk by Dieter Plaetinck last month.
I had no more excuses to delay it any longer, so I switched. All my
machines have /boot as the first partition on the disk, they
are flagged bootable, and use the ext2 file-system. Migrating
to syslinux was simple:
# pacman -Syu syslinuxThe syslinux-install_update options stand for installing it to the MBR, where it replaces LILO. Then I wrote a configuration file: /boot/syslinux/syslinux.cfg. Actually, I wrote one in advance, because even though you might find it funny, it was a big deal for me to continue using my boot prompt as is. I've been using the LILO fingerprint menu for years. Not being able to port it would be a deal breaker. But it wasn't complex, actually.
# /usr/sbin/syslinux-install_update -i -a -m
# cp -arp /etc/lilo.conf /etc/lilo.conf.bak
# pacman -Rns lilo
If you want to use the Fingerprint theme, grab it from KDE-Look, convert the BMP to the PNG format and save it as splash.png. I'll include my whole syslinux.cfg for reference, but the important bits for the theme are menu and graphics sections. I didn't bother to tweak the ANSI settings as I don't intend to use them, so I copied them from the Arch Linux menu. Settings below will give you a pretty much identical look and feel (shadows could use a bit more work), and also provide a nice bonus over LILO when editing the boot options (by pressing Tab, as in LILO):
#
# /boot/syslinux/syslinux.cfg
#
# General settings
UI vesamenu.c32
DEFAULT linux
PROMPT 0
TIMEOUT 250
# Menu settings
MENU WIDTH 28
MENU MARGIN 4
MENU ROWS 3
MENU VSHIFT 16
MENU HSHIFT 11
MENU TIMEOUTROW 13
MENU TABMSGROW 11
MENU CMDLINEROW 11
MENU HELPMSGROW 16
MENU HELPMSGENDROW 29
# Graphical boot menu
#
# Fingerprint menu
# http://kde-look.org/content/show.php/Fingerprint+Lilo-splash?content=29675
MENU BACKGROUND splash.png
#
# element ansi f/ground b/ground shadow
MENU COLOR sel 7;37;40 #ffffffff #90000000 std
MENU COLOR unsel 37;44 #ff000000 #80000000 std
MENU COLOR timeout_msg 37;40 #00000000 #00000000 none
MENU COLOR timeout 1;37;40 #00000000 #00000000 none
MENU COLOR border 30;44 #00000000 #00000000 none
MENU COLOR title 1;36;44 #00000000 #00000000 none
MENU COLOR help 37;40 #00000000 #00000000 none
MENU COLOR msg07 37;40 #00000000 #00000000 none
MENU COLOR tabmsg 31;40 #00000000 #00000000 none
# Boot menu settings
LABEL linux
MENU LABEL GNU/Linux
LINUX ../vmlinuz26
APPEND root=/dev/sda2 ro rootflags=data=ordered i915.modeset=1 video=VGA-1:1152x864 drm_kms_helper.poll=0
INITRD ../kernel26.img
LABEL recovery
MENU LABEL Recovery
LINUX ../vmlinuz26
APPEND root=/dev/sda2 ro rootflags=data=ordered
INITRD ../kernel26-fallback.img
You can find the documentation, and menu options explained on
the syslinux
wiki. If you achieve an even more faithful copy send me an e-mail
with the new values. Thank you.
02.04.2011 20:59
Introducing play, a fork of cplay
I've been using cplay for close to ten years now. It
is a curses front-end to various audio players/decoders, and written
in Python. Sure, I've been
an Amarok fan for half that time,
but when I just want to hear some music I find my self opening a
terminal and starting cplay. I manage my music collection in Amarok, I
grab and listen new podcasts in Amarok. Sometimes I even use it to
play music, but not nearly as much as I do with cplay. I have 4
workstations at home, and they all do the same. Same thing with the
server connected to the best set of speakers. Sure, I have a remote
and Oxine there, but when
I just want to hear some music I don't want to spend 5 minutes messing
with the remote.
Through the years I added various small patches to my copy of
cplay. They accumulated over time, and except for my
color-support
patch I didn't plan on sharing them. But in 2009 I found that the
project page of cplay disappeared. I spent a year thinking it will
pop-up, but it didn't. Then I noticed the Arch Linux package for cplay
pulls the source from the Debian repositories, and realized it's not
coming back.
I decided to publish my copy of cplay, so there exists yet another
place where it's preserved. But as I'm not acting in any official
role, nor do I consider my self a worthy coder to maintain cplay I
decided to fork it and publish under a new name. That also gives me
the excuse to drop anything I don't personally use,
like gettext support. My project is
called play, just play and the Git
repository is now public,
on git.sysphere.org. The
first commit is an import of cplay-1.50pre7
from Ulf Betlehem, so if you're looking for that original
copy you can grab it there.
Beside various bug fixes some of the more interesting new features
are: color support, mplayer
support, curses v5.8 support
and pyid3lib support. Someone on IRC told me this week that
they could never get cplay to work for them on Arch Linux, and they
expressed interest in play. I decided to package it
on AUR, and it's now available
as play-git.
29.03.2011 05:07
Securing Debian repositories
I had to build some Debian packages recently after a long
time. The experience really made me appreciate
the simple
approach taken by Arch Linux. When I finally built
something up to Debian standards I had to distribute it on the
network. Debian's APT can work over HTTP, FTP... but
also SSH, which is pretty good for creating strong access controls for
the repository, over encrypted connections. There are a lot
of articles
covering this approach, but I didn't find any information on how to
make it work in a chroot environment, and got stuck
there for a while.
But to go back to the beginning, if you're setting up a repository the
reprepro tool is
pretty good for repository management. Having SSH in mind for later,
some decisions have to be made where you'll store the repository and
who will own it. The "reprepro" user is as good as any, so we
can start by adding the user (and group) to the system and making its
home
/srv/reprepro. Then we can setup the bare repository layout,
in this example the repository will reside in the debs
directory:
# su repreproYou'll need two files in the conf sub-directory, those being "distributions" and "options". They are simple to write, and all the other articles explain them. You don't have to worry about the rest of the tree, once you import your first package, or .changes file, reprepro will take care of it then. If you intend to use GPG, and sign your Release file, it's a good time to create your signing key. Then in the distributions file configure the Sign option, and in the conf file add ask-passphrase.
$ cd ~
$ mkdir -p debs/conf
Now we can add another user, one for APT clients, its home can be the same as our reprepro user has. User should be allowed to connect in the SSH daemon configuration file, and properly chrooted using the ChrootDirectory option. Here are the (only) binaries you will need in /srv/reprepro/bin: bash, find and dd. I mentioned getting stuck, well this was it, APT is using find and dd binaries internally, which strace revealed.
You can now publish your repository in /etc/apt/sources.list, for example:
deb ssh://apt@192.168.50.1:/debs/ squeeze main deb-src ssh://apt@192.168.50.1:/debs/ squeeze mainThat's the gist of it. User apt gets read-only access to the repository, if coming from an approved host. You can control host access with TCPWrappers, Iptables and OpenSSH's own whitelist that ties keys to specific hosts. Each APT client should have its key white-listed for access, but give some thought to key management, they don't have to be keys without a passphrase. You can setup the SSH agent on a machine you trust, and unlock a key. Using agent forwarding provided by the OpenSSH client you could login to a machine and install packages without being prompted for the passphrase, and without leaving your keys laying around. This alone would not scale in production, but is a good start.