05.03.2012 00:06
Infrastructure you can blog about
I spent last 5 months planning and building new infrastructure for one
of the biggest websites out there. I was working around the clock
while developers were rewriting the site, throwing away an ancient
code base and replacing it with a modern framework. I found no new
interesting topics to write about in that time being completely
focused on the project, while the RSS feed of this journal was
constantly the most requested resource on the web server. I'm sorry
there was nothing new for you there. But I learned some valuable
lessons during the project, and they might be interesting enough to
write about. Everything I learned about Puppet, which was also a part
of this project, I shared in
my previous
entry. I'll focus on other parts of the cluster this
time.
Here's a somewhat simplified representation of the cluster:
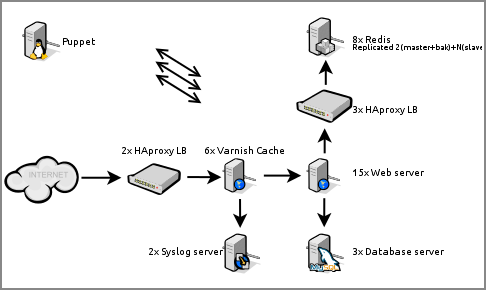
Following the traffic path first thing you may ask your self is
"why is Varnish Cache behind HAproxy?". Indeed placing it in
front in order to serve as many clients as soon as possible is
logical. Varnish Cache is
good software, but often unstable (developers are very quick to fix
bugs given a proper bug report, I must say). Varnish Cache plugins (so
called vmods) are even more unstable, crashing varnish often
and degrading cache efficiency. This is why HAproxy is imperative in
front, to route around crashed instances. But it's the same old
HAproxy that has proven it self balancing numerous high availability
setups. Also, Varnish Cache as a load balancer is a nice try, but I
won't be using it as such any time soon. Another thing you may ask is
"how is Varnish Cache logging requests to Syslog when it has no
Syslog support?". I found FIFOs work good enough - and remember
traffic is enormous, so that says a lot.
Though with a more mature threaded implementation I can't see my self
using Rsyslog
over syslog-ng
on big log servers in the near future. Hopefully threaded syslog-ng
only gets better, resolving this dilemma for me for all
times. Configuration of rsyslog feels awkward (though admittedly
syslog-ng is not a joy to configure either). Version packaged in
Debian stable has bugs, one of which made it
impossible to apply different templates to different network
sources. Which is a huge problem when it's going to be around for
years. I had to resort to packaging my own, but ultimately dropped it
completely for non threaded syslog-ng which is
working pretty good.
Last thing worth sharing are Redis
experiences. It's really good software (ie. as alternative
to Memcached) but ultimately I
feel disappointed with the replication implementation. Replication,
with persistence engines in use, and with databases over 25GB in size
is a nightmare to administrate. When a slave (re)connects to a master
it initiates a SYNC which triggers a SAVE on the
master, and a full resync is performed. This is an extremely expensive
operation, and makes cluster wide automatic fail-over to a backup
master very hard to implement right. I've also
experienced AOF
corruption which could not be detected
by redis-check-aof. This makes BGREWRITEAOF jobs
critical to execute regularly, but with big databases this is another
extremely expensive operation, especially if performed under
traffic. The following has proven it self as a best solution for high
performing Redis servers; 4+x147GB 15k SAS disks in (h/w) RAID10, and
Xeon 5000 series CPUs.
While working on this the running joke was I'm building infrastructure
you can blog about (but otherwise do little else with it). But it does
do a little more than just look impressive on paper.